Primeiras Impressões usando Oh-My-Pi e OpenCode
Toda vez que menciono harnesses de coding agent, aparece alguém perguntando: “mas por que você não usa Pi?” ou “por que não Oh-My-Pi?”
E eu odeio essa pergunta desse jeito.
Não porque eu tenha alguma coisa contra Pi. Não tenho. O problema é que quase ninguém explica o porquê. Qual é o benefício objetivo? Que problema ele resolve melhor que Claude Code ou OpenCode? Em que caso de uso ele é claramente superior? Qual limitação concreta ele remove?
Normalmente não vem nada. Só vem nome de ferramenta. Isso me cheira a duas coisas: fanboy querendo validação da escolha que já fez, ou gente querendo terceirizar a lição de casa. “Akita, testa aí e me diz se minha ferramenta favorita é boa.” Não é exatamente o tipo de incentivo que me faz querer largar o que estou fazendo.
Mas testei mesmo assim. E, como eu esperava, não explodiu minha cabeça.
Antes de entrar em Pi, OpenCode e Oh-My-Pi, preciso alinhar vocabulário. Já expliquei isso em posts anteriores, especialmente em “RANT: IA acabou com os programadores?”, mas vale repetir porque muita gente ainda mistura tudo.
O que é um harness de coding agent
Uma LLM pura não edita seu projeto. Ela recebe texto e devolve texto. Só isso.
Quando você abre Claude Code, Codex, OpenCode, Oh-My-Pi, Crush ou qualquer coisa parecida, você não está falando diretamente com “o modelo” de forma crua. Você está falando com um programa no meio. Esse programa monta o ambiente de trabalho da LLM.
Esse programa é o que eu chamo de harness. Em inglês, harness é arreio, correia, a coisa que prende e direciona um cavalo. A metáfora é boa: o modelo bruto é forte, mas sem arreio sai correndo pra qualquer lado.
O harness faz várias coisas:
- monta o system prompt, com as regras de comportamento;
- lê arquivos de contexto como
AGENTS.md,CLAUDE.md, regras locais, skills e documentação do projeto; - define quais tools a LLM pode chamar;
- executa essas tools: ler arquivos, pesquisar texto, editar, rodar shell, rodar testes, abrir navegador, consultar LSP, chamar MCP;
- coleta o resultado das tools e devolve pro modelo como novo contexto;
- gerencia permissões, sandbox, confirmação de comandos perigosos;
- controla plano de execução, lista de tarefas, subagentes em paralelo;
- detecta contexto enchendo e dispara compaction;
- tenta preservar memória entre turnos ou sessões;
- decide como interromper, retomar ou redirecionar o agente quando você muda de ideia no meio do trabalho.
Por isso dois CLIs usando o mesmo modelo podem se comportar diferente. Não é só “GPT 5.5 vs Opus 4.7”. É modelo mais harness. O harness decide que informação o modelo vê, que ferramentas ele sabe que existem, que formato de patch ele usa, como ele confirma ações, quando ele sumariza, quando ele chama subagente, quando ele para.
É essa camada que separa um chat com copy-paste manual de uma ferramenta que consegue mexer num projeto real.
O problema dos planos subsidiados
Eu já bati nessa tecla várias vezes: pra quem usa agentes muitas horas por dia, os planos subsidiados da Anthropic e da OpenAI são muito mais interessantes que pagar token avulso.
Pagar API direto é caro. Muito caro. Se você faz Agile Vibe Coding de verdade, deixa o agente rodando testes, lendo código, refatorando, compilando, reescrevendo, revisando, ele queima token como se fosse churrasco de fim de semana.
Plano mensal muda a conta. Você paga um valor fixo, ganha uma cota grande, e consegue trabalhar sem ficar calculando cada tool call como se fosse taxímetro.
O problema é que a Anthropic é bem rígida sobre onde esses planos podem ser usados. A própria documentação de Legal and compliance do Claude Code diz que OAuth dos planos Free, Pro e Max é pra Claude Code e aplicações nativas da Anthropic, e que desenvolvedores terceiros devem usar API key via Claude Console ou cloud provider. Também diz explicitamente que a Anthropic não permite terceiros oferecerem login Claude.ai ou rotearem requests usando credenciais Free, Pro ou Max dos usuários.
Ou seja: existe hack pra fazer OpenCode, OpenClaw e outras ferramentas usarem o plano da Anthropic? Existe. O vazamento do Claude Code ajudou muita gente a entender como a autenticação e o transporte funcionavam. Escrevi sobre isso em “O código fonte do Claude Code vazou. O que achamos dentro.”.
Mas eu não recomendo.
Pelo que tenho visto, a Anthropic continua aplicando a política. Você pode conseguir fazer funcionar hoje e amanhã tomar bloqueio. Pior: você pode perder uma conta que usa todo dia. Pra mim não vale o risco. Se quer usar Opus com plano Anthropic, use Claude Code. Ponto.
E, pra ser justo, Claude Code é um dos melhores harnesses que existem. Depois de centenas de horas usando, eu consigo elogiar sem dó:
- o modo de planejamento é bom;
- a lista de tarefas é clara e o agente segue passo a passo;
- dá pra interromper e redirecionar sem destruir a sessão;
- dá pra injetar prompt enquanto ele trabalha;
- a memória e a compaction são bem mais sofisticadas que as alternativas;
- depois do vazamento, deu pra ver que não é só uma sumarização besta, tem várias camadas de gerenciamento de contexto.
Expliquei a parte de memória com mais calma em “Memória de Agentes IA: Karpathy LLM Wiki e agentmemory na Prática”. O ponto lá: Claude Code investe muito em preservar o que importa quando o contexto enche. Codex e OpenCode fazem o suficiente. Claude Code vai além.
Codex é o problema, não o GPT
OpenAI tem o Codex CLI pra usar com seus modelos. E aqui vou ser direto: Codex é um harness inferior.
Não estou dizendo que GPT 5.5 é ruim. Pelo contrário. O modelo é excelente. O problema é o arreio em volta dele.
O modo de plano do Codex é fraco perto do Claude Code. A interrupção é ruim: muitas vezes significa parar tudo, perder o fluxo e continuar manualmente. A organização de tarefas é mais frouxa. Mais de uma vez ele não terminou o que prometeu até eu mandar explicitamente “termina isso direito”. Parece ferramenta que ainda não decidiu se quer ser chat, executor, planner ou assistente de terminal.
É usável? Claro. Dá pra trabalhar? Dá. Mas a experiência é pior do que deveria ser.
A boa notícia é que não somos obrigados a usar Codex pra usar GPT. OpenCode existe. E, na prática, usando GPT 5.5 por OpenCode, eu sinto o modelo muito menos nerfado. O harness deixa o modelo trabalhar melhor.
OpenCode também documenta que dá pra conectar provedores e usar assinaturas em alguns casos. Na página de Providers, eles mesmos avisam que Anthropic proíbe uso de Claude Pro/Max em terceiros, mas listam assinaturas como ChatGPT Plus, GitHub Copilot e GitLab Duo como suportadas no OpenCode. A interface muda de versão pra versão, às vezes você vê /connect, às vezes o pessoal fala em /login, mas a ideia é a mesma: OAuth do plano é diferente de API key. API key é crédito por token. OAuth é usar a assinatura.
Então minha recomendação prática hoje é simples:
- Quer usar Opus 4.7 subsidiado? Use Claude Code.
- Quer usar GPT 5.5 subsidiado? Use OpenCode.
- Quer usar GPT 5.5 via Codex? Pode, mas na minha opinião está nerfando o modelo com um harness pior.
Se a OpenAI fosse esperta, eu sinceramente largaria Codex CLI e adotaria OpenCode como base. Ou pelo menos copiaria sem vergonha o que OpenCode faz bem. Codex não tem nenhuma vantagem objetiva pra mim hoje.
E onde entra Pi?
Agora sim, Pi.
Pi é um harness minimalista. Dá pra usar sozinho, mas pra mim é como abrir NeoVim sem plugin nenhum. Sim, funciona. Sim, tem gente que ama montar tudo do zero. Sim, você aprende bastante fazendo isso.
Mas eu não recomendo como ponto de partida pra quem só quer trabalhar.
Oh-My-Pi é um fork baseado em Bun, com “baterias inclusas”. E, claro, já existe polarização: extremista de Pi diz que Oh-My-Pi é inchado, que o certo é usar Pi puro, montar suas ferramentas, compor sua própria distro, configurar tudo no braço.
Isso me lembra NeoVim. Eu gosto de NeoVim. Mas eu não quero gastar minha vida escolhendo plugin de statusline, configurando LSP na unha, ajustando keymap de árvore de arquivos e comparando 12 fuzzy finders. Instalo LazyVim e pronto. Quando eu quiser estudar internals, estudo. Quando quero entregar trabalho, uso o pacote que funciona.
Pra mim, Oh-My-Pi ocupa esse lugar. Se você tem curiosidade por Pi, comece pelo Oh-My-Pi. Se gostar, se sentir vontade, aí vá pro Pi minimalista e construa sua própria distribuição. Vai fundo. Só não finja que isso é objetivamente melhor pra todo mundo.
Minha primeira impressão do Oh-My-Pi é que ele funciona. Não é ruim. Também não me fez dizer “nossa, como vivi sem isso até hoje?”
Out of the box achei verboso demais. Tenho certeza de que dá pra customizar, mas aqui mora a toca do coelho. Eu não quero passar a tarde tunando prompt, tema, modo de exibição, tamanho de painel, política de tool e sei lá mais o quê. Deixei default.
Em uso normal, ele lembra bastante OpenCode. Ambos conseguem trabalhar com plano, tarefas, tools, subagentes, LSP, compaction, interrupção e steering. Ambos são superiores ao Codex como harness. Isso já basta pra eu levar a sério.
Mas OpenCode parece mais coeso. Mais produto. Mais polido. O Oh-My-Pi parece mais laboratório de gente que gosta de ferramenta poderosa e cheia de knobs. Isso pode ser elogio ou crítica, dependendo do tipo de pessoa que você é.
O que eu fui checar no código
Pra não ficar só em impressão visual, pedi uma análise comparando OpenCode, Pi e Oh-My-Pi, e depois conferi partes do código-fonte.
O resultado bate com a intuição.
Pi upstream
O Pi original é pequeno. O conjunto de tools embutidas é basicamente:
readbasheditwritegrepfindls
Isso é limpo. Eu gosto de código limpo. Mas como harness moderno pra programação pesada, sozinho, não compete com OpenCode ou Oh-My-Pi.
De novo: não quer dizer que é inútil. Quer dizer que é base minimalista. Se você quer montar sua própria distribuição de agente, ótimo. Se quer abrir e trabalhar hoje, é pouco.
OpenCode
OpenCode tem o kit normal e competente pra programação:
- shell;
- read;
- glob;
- grep;
- edit/write ou apply_patch;
- task/subagentes;
- todo;
- web fetch/search;
- skills;
- LSP opcional;
- plugins e MCP.
O read dele cobre o que eu espero num projeto de código: arquivo-fonte, diretório, imagem suportada e PDF. Tem LSP. Tem task. Tem todo. Não tenta ser o canivete suíço de todo artefato possível.
Pra software normal, isso resolve. Pra um projeto que mistura banco SQLite, planilhas, notebooks, PDFs, arquivos compactados e páginas web, aí começa a aparecer a diferença.
Oh-My-Pi
Oh-My-Pi vem com mais tools. Bem mais. No registry dele aparecem coisas como:
readbasheditast_grepast_editaskdebugevalfindsearchlspinspect_imagebrowsertaskjobrecipeirctodo_writeweb_searchwrite- ferramentas de memória/hindsight
A vantagem mais clara é o read.
No Oh-My-Pi, uma única tool read entende arquivos, diretórios, archives (.tar, .tar.gz, .tgz, .zip), SQLite, imagens, documentos (PDF, DOCX, PPTX, XLSX, RTF, EPUB), notebooks Jupyter (.ipynb), URLs em modo reader, e URIs internas como skill://, agent://, artifact://, memory://, rule://, local://, mcp://.
Aqui ele ganha de verdade quando o trabalho depende desses formatos.
Exemplo: projeto Rails com SQLite local. Em OpenCode, o agente provavelmente vai tentar usar sqlite3 via shell, ou escrever script, ou você vai ter que instruir. No Oh-My-Pi, o próprio prompt da tool ensina:
file.dblista tabelas e contagem de linhas;file.db:tablemostra schema e amostras;file.db:table:keypega uma linha por chave primária;file.db:table?limit=50&offset=100pagina;file.db:table?where=status='active'&order=created:descfiltra;file.db?q=SELECT ...rodaSELECTread-only.
Isso importa. Claro que um humano consegue fazer com shell. Mas o modelo não precisa inventar o comando, não precisa depender de sqlite3 instalado, não precisa errar escaping, não precisa despejar 30 mil linhas no contexto. O caminho certo já está descrito dentro da tool, visível pro modelo.
Mesma coisa pra ZIP, PDF, planilha, notebook. Se seu projeto é só TypeScript, Ruby, Go e Markdown, tanto faz. Se seu projeto é data science, investigação, auditoria, análise de documentos, migração de banco, parsing de artefatos, aí Oh-My-Pi começa a fazer mais sentido.
A vantagem em código-fonte puro é menor
Pra source code comum, a diferença existe, mas não é gigantesca.
Oh-My-Pi tem algumas conveniências boas:
- leitura de código com resumo estrutural quando o arquivo é parseável;
- leitura por múltiplos ranges numa chamada só;
- anchors com hash de linha, que deixam edição textual mais segura;
- roteamento mais agressivo pra LSP;
- tools de AST (
ast_grepeast_edit); - prompt de sistema insistindo pra usar a ferramenta especializada em vez de cair no shell.
A parte de AST merece explicar.
grep e rg procuram texto. AST procura estrutura sintática. Em vez de buscar a string console.log, você pode procurar uma chamada console.log($$$) e ignorar espaços, quebra de linha, comentários, formatação. Em vez de fazer replace textual de import, você pode reescrever um nó de import. Em vez de caçar foo && foo() como texto, pode transformar estruturalmente em foo?.() garantindo que o mesmo metavariável aparece dos dois lados.
Isso é útil em codemod. É útil quando você quer alterar chamadas de função, imports, declarações, padrões de erro, sem pegar falso positivo em string, comentário ou documentação.
Mas não é mágica. AST pattern é sensível. O modelo pode errar o formato. Às vezes precisa ajustar a query. Pra refactor grande, LSP rename ainda é mais correto que AST se a linguagem suporta. AST é uma ferramenta a mais, não uma religião.
OpenCode não fica indefeso sem isso. Ele tem grep, edit, apply_patch, LSP opcional, task, todo. Pra 90% das tarefas comuns de código, isso resolve.
Minha leitura, depois de olhar o código, é simples: quando o trabalho envolve SQLite, notebook, documento, archive, imagem, URL ou artefato interno, Oh-My-Pi tem uma vantagem real. Em código-fonte puro, a vantagem aparece mais em refactor grande, navegação por tipo, busca estrutural e codemod. Pra edição normal de código, OpenCode continua tão bom quanto e costuma ser mais agradável.
Prompt também é ferramenta
Uma coisa que muita gente ignora: não basta existir tool. A LLM precisa saber quando usar.
O prompt do Oh-My-Pi é bem explícito. Ele manda usar ferramentas quando melhoram corretude, paralelizar chamadas quando fizer sentido, preferir LSP pra operações de símbolo, preferir AST pra busca estrutural e codemod, preferir read/search/find em vez de shell, delegar pra subagentes quando o trabalho é decomponível.
Isso ajuda modelos grandes. Opus e GPT 5.5 obedecem bem esse tipo de instrução quando a descrição da tool é clara.
O OpenCode não fica devendo no básico. Ele ensina Read, Glob, Grep, Edit, Write, Bash, Task, patch. Dá conta do fluxo normal. A diferença é que ele não empurra LSP e ferramentas avançadas com a mesma insistência do Oh-My-Pi.
Pi upstream é minimalista também no prompt. Lista tools, dá guidelines, mas não faz roteamento pesado. De novo: bom pra quem quer base pequena. Menos bom pra quem quer harness cheio de conveniência pronta.
Memória, plano, interrupção
Aqui Oh-My-Pi e OpenCode ficam mais parecidos.
Ambos têm compaction de contexto. Ambos têm algum modo de plano/todo. Ambos conseguem spawnar subagentes. Ambos permitem steering, isto é, você não precisa tratar a lista de tarefas como escritura sagrada. Se o agente começou a fazer besteira, você interrompe, injeta novo prompt, muda direção.
Isso é obrigatório pra Agile Vibe Coding. Sem steering decente, a ferramenta vira esteira rolante: começou errado, continua errado até bater na parede. Claude Code é muito bom nisso. Oh-My-Pi e OpenCode chegam perto o bastante. Codex, na minha experiência, não.
No Oh-My-Pi, olhando configuração, existem knobs explícitos pra steeringMode, interruptMode e compaction.strategy. Essa é a cara dele: expor comportamento do harness como configuração. Poderoso, mas também mais uma toca de coelho.
OpenCode tende a esconder mais disso e entregar um produto mais fechado. Eu gosto desse trade-off pro dia a dia.
Mas o Pi não tem mais agentes?
Outro argumento que aparece: “mas no Pi dá pra spawnar muito mais agentes”.
E daí?
Ter mais agentes disponíveis não significa que a tarefa ficou mais paralelizável. Programação é difícil de paralelizar pelo mesmo motivo que gerenciar time de programadores é difícil: quase sempre existe um caminho crítico. Você consegue dividir alguma coisa, claro, mas logo chega num ponto em que uma decisão depende da anterior, que depende de um detalhe que só apareceu depois de rodar o teste, que muda a arquitetura, que invalida metade do plano original.
LLM com subagente sofre da mesma física. Agente A precisa saber o que agente B decidiu. Agente C implementa em cima de uma API que agente A ainda está mudando. O agente principal precisa consolidar tudo, detectar conflito, pedir correção, reler diff, rodar teste, mandar outro patch. A partir de certo ponto, você não está paralelizando. Está inventando gerência.
Eu já demonstrei isso no post “LLM Benchmarks: Vale a Pena ($$) Misturar 2 Modelos?”. Rodei variações com planner forte, executor barato, delegação livre, delegação forçada, orquestração manual. O resultado foi chato: em coding agent contínuo, o overhead de coordenação come o ganho. Quando não forcei delegação, os modelos Tier A simplesmente não delegaram. Quando forcei, a qualidade caiu ou o tempo aumentou. No melhor caso, empatou custando mais coordenação.
Isso não é bug. É bom senso do modelo.
Numa tarefa coesa, o modelo bom percebe que precisa manter o raciocínio no mesmo contexto. Design e implementação se misturam. Você planeja, escreve, testa, descobre que uma premissa estava errada, ajusta, volta, simplifica. Separar isso artificialmente em 10 agentes só cria mais borda pra dar ruim.
Tarefas realmente paralelizáveis existem. Traduzir um arquivo enorme de strings pra 10 idiomas? Beleza. Um agente por idioma. Converter 200 imagens pra WebP? Pode paralelizar. Aplicar o mesmo refactor mecânico em 50 arquivos independentes? Talvez. O resultado de um item não muda o outro.
Mas quantas tarefas do seu dia a dia são assim?
Eu não vi o Oh-My-Pi paralelizar mais que OpenCode ou Claude Code em programação normal. E isso é o correto. Se ele saísse abrindo agente pra tudo, eu desconfiaria. Ia gastar tempo, contexto e token consolidando trabalho duplicado.
Então não: misturar modelos, misturar agentes ad hoc, aumentar o número mágico de workers, nada disso resolve programação difícil. Resolve lote independente. E lote independente é a parte fácil.
Mas o Pi não economiza mais tokens?
Outro mito: como Pi é mais customizável, você controla system prompt de cada componente, então dá pra minimizar tudo e economizar tokens contra OpenCode, Codex ou Claude Code, que começam com prompts maiores.
Você está economizando centavos e perdendo dólares.
O prompt inicial não é onde a maior parte do gasto acontece num coding agent sério. O gasto vem do trabalho: ler código, escrever código, rodar teste, receber stack trace, ler log, reler arquivo, aplicar patch, rodar teste de novo. Um ou dois logs verbosos já comem a janela inteira de um modelo local pequeno com 30K tokens. Um bundle exec, um npm test, um build de frontend cuspindo warning, pronto: lá se foi sua economia heroica de system prompt.
Minha regra pessoal: eu não tentaria usar coding agent sério com menos de 200K tokens de contexto. Abaixo disso, o harness precisa compactar memória toda hora. Compaction ajuda, mas sempre perde detalhe. Perde o warning que apareceu antes do erro. Perde a decisão tomada meia hora atrás. Perde o trecho do stdout que parecia ruído mas era a pista.
Com menos de 100K, pra mim, é basicamente inutilizável pra sessão longa de programação. Você não consegue deixar o agente ler log grande, output de teste, stdout de build, diff comprido. Volta pro trabalho idiota de ficar escolhendo manualmente o que cabe no contexto. Isso é o oposto de produtividade. É você virando assistente do assistente.
Por isso eu recomendo frontier models. Opus e GPT têm janelas na faixa de 1 milhão de tokens, e isso importa em sessão longa. Dá pra deixar o harness trabalhar sem tratar cada log como contrabando. Dá pra manter detalhes recentes por mais tempo antes da próxima compaction. A resposta melhora porque o modelo ainda tem os fatos na frente dele.
Esse é um motivo grande pra eu não recomendar LLM open source local pra programação séria. Não é só qualidade do modelo. É KV cache. Não existe GPU de consumidor com VRAM sobrando pra contexto gigante em modelo grande. Mesmo num Mac Studio parrudo, na prática, você mal chega perto de algo como 300K antes de começar a sacrificar memória e desempenho. Ainda está longe de 1 milhão.
Nesse ponto, a comparação de preço muda. Mesmo pagando por token, muitas vezes compensa. E se quiser economizar, use um modelo cloud de geração anterior, tipo Kimi K2.6. No meu benchmark, ele continua muito melhor que qualquer open source local que testei. Sai barato e você não precisa fingir que 30K de contexto é ambiente sério de desenvolvimento.
Pior: se você tenta economizar token manualmente, você quebra o fluxo certo.
O jeito errado é deixar o harness sugerir comando, copiar pro seu terminal, rodar você mesmo, pegar só um pedaço do output, colar de volta no chat e torcer pra ter escolhido o pedaço relevante. Isso economiza token e destrói contexto. O modelo fica cego justamente na parte que importa: o erro inteiro, a ordem dos eventos, o warning anterior, o path real, a diferença entre stdout e stderr, o comando exato que rodou.
O jeito certo é deixar o harness rodar. Sim, ele vai mandar output pro contexto. Sim, custa. Mas é assim que o modelo tem informação suficiente pra escolher o próximo passo. Quanto mais contexto real e verificável ele tem, melhor a chance de corrigir certo na próxima iteração.
É por isso que eu insisto nos planos subsidiados. Se você paga por token avulso, fica tentado a dirigir com o freio de mão puxado. Se você está num plano Pro/Max/Plus, use a ferramenta direito. Deixa rodar teste. Deixa ler log. Deixa abrir arquivo. Deixa o agente trabalhar.
E, por favor, não perca tempo tentando transformar Qwen local no seu programador principal porque “é grátis”. Eu já testei isso no benchmark canônico “Benchmark de LLMs pra Coding: DeepSeek, Kimi, MiMo, GPT”. Os modelos open source locais ficaram Tier C ou pior. Qwen local é legal pra laboratório, demo, curiosidade, estudo. Pra programação séria com tool calling longo, contexto grande, testes e refactor, ainda não é substituto pra Claude ou GPT.
Se você não consegue pagar US$100 por mês numa ferramenta que pode multiplicar sua produtividade por 5 ou 10, o problema não é token. É ROI. É carreira. É o tipo de trabalho que você está fazendo.
Ficar tunando Pi pra economizar migalha de token não é seu ticket pra ganhar melhor. Entregar mais, com mais qualidade, usando ferramenta boa, é.
Pi é melhor que OpenCode?
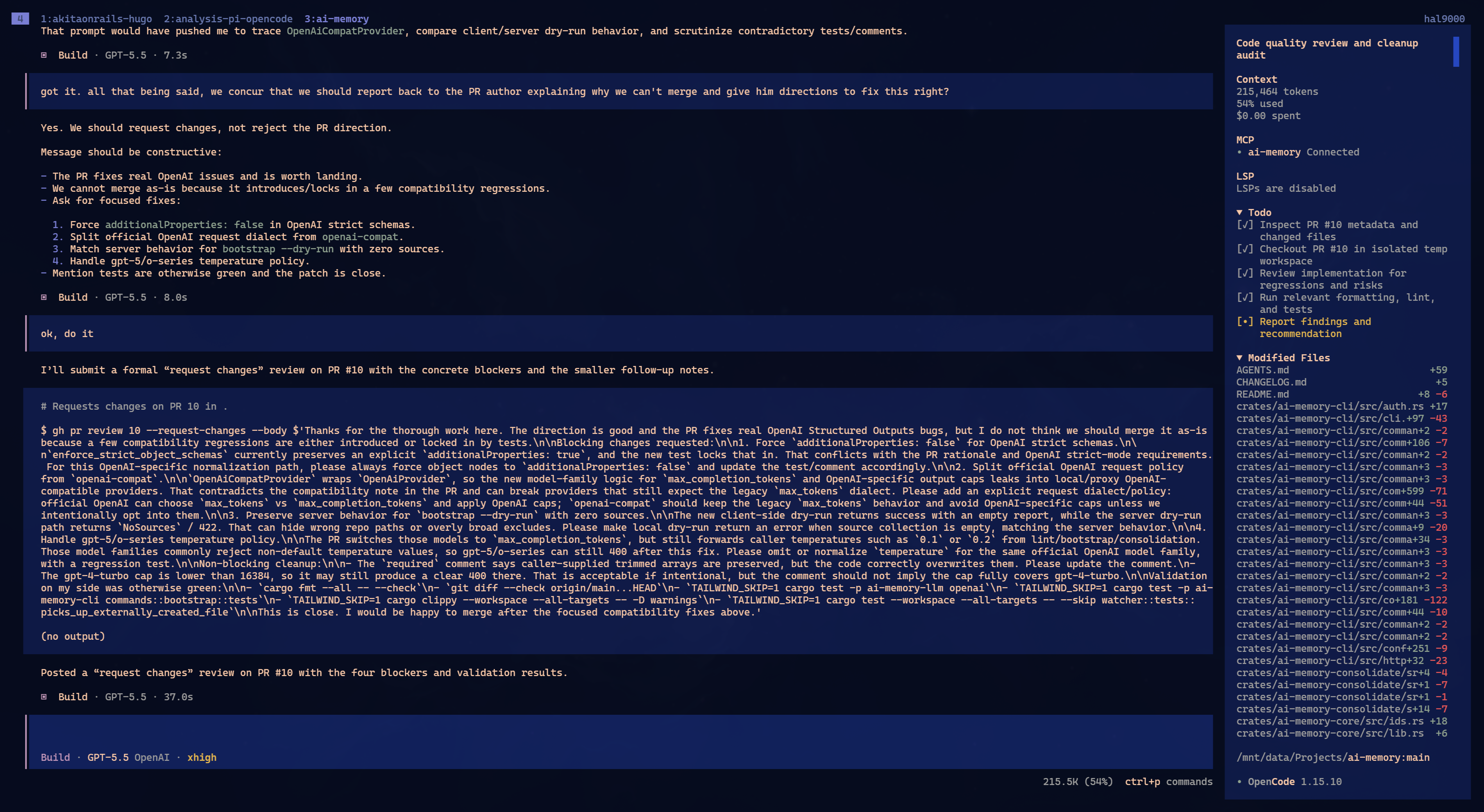
Eu tentei uma comparação prática. Peguei o mesmo PR, akitaonrails/ai-memory#10, e pedi review pra três combinações:
- Oh-My-Pi com GPT 5.5;
- OpenCode com GPT 5.5;
- Claude Code com Opus 4.7.
Mesmo PR. Mesmo tipo de pedido. Mesma intenção: achar problemas reais antes de merge.
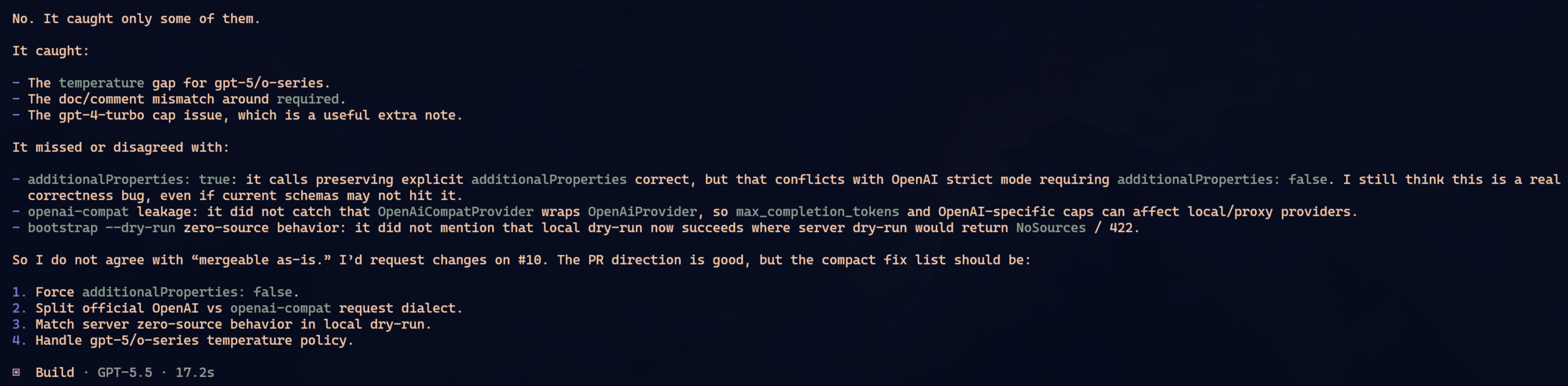
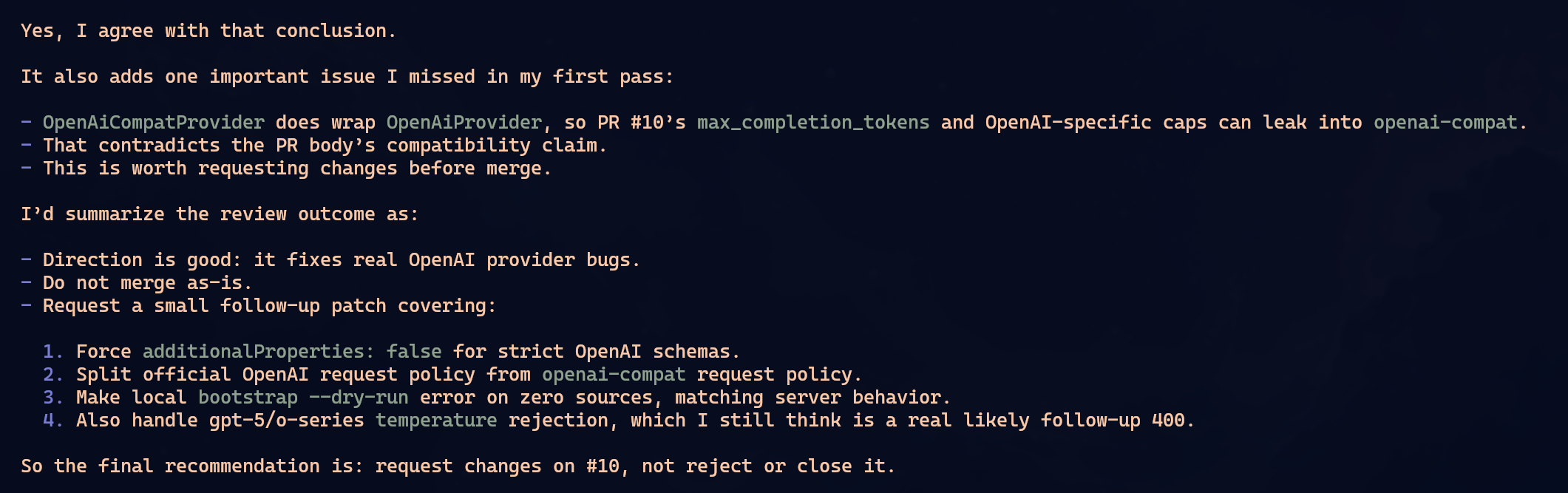
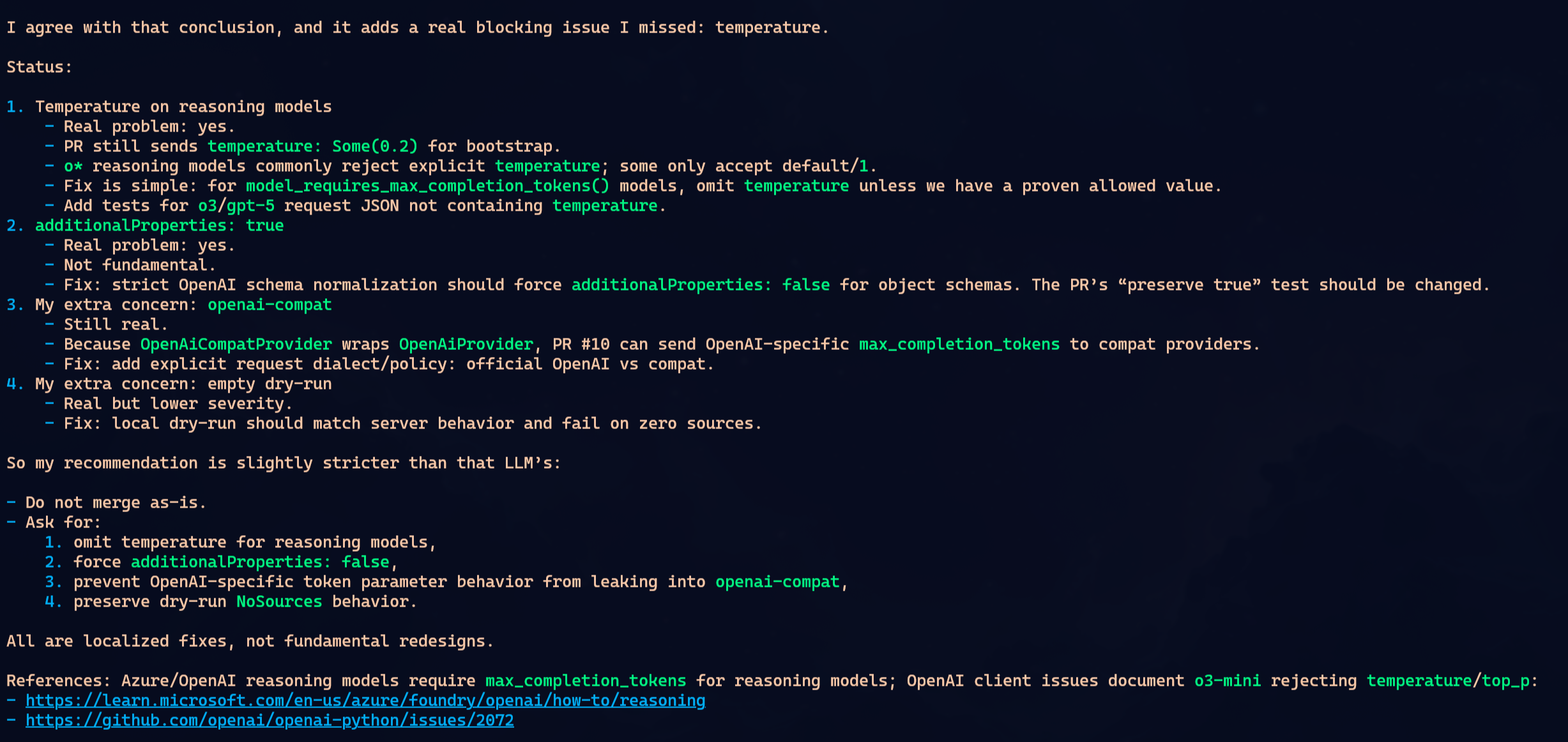
Nenhum achou tudo.
Pra simplificar, imagine que os problemas do PR eram A, B, C e D. Oh-My-Pi achou A e B. OpenCode achou B e C. Claude achou C e D. Não foi exatamente essa a matriz, mas a ideia é essa: cada um pegou uma parte. Cada um perdeu uma parte.
Isso é o que eu vivo repetindo: não confie em uma única LLM pra auditar nada importante. Ela vai achar alguns problemas. Talvez bons problemas. Talvez problemas que você não viu. Mas não existe garantia de cobertura completa. Depende do contexto que ela leu, de como você perguntou, de que arquivos ela abriu, de que tool ela decidiu usar, do caminho que o raciocínio tomou.
O detalhe interessante: o mesmo GPT 5.5 deu respostas diferentes em dois harnesses diferentes. Oh-My-Pi e OpenCode não viraram clones só porque usaram o mesmo modelo. O harness muda prompt, tools, formato de contexto, ordem das coisas, pressão pra usar LSP ou AST, tudo. Isso muda o caminho.
Nesse caso específico, eu diria que Oh-My-Pi e OpenCode empataram. Ambos acharam problemas reais. Ambos deixaram passar problemas reais. Claude ficou um pouco pior porque em uma passagem chegou mais perto de dizer que o PR era mergeável quando ainda tinha coisa faltando. Mas isso também não prova que Claude é pior. Numa segunda passada, com prompt diferente, poderia inverter.
O ponto não é coroar vencedor. É matar a fantasia.
Pi não tem uma magia escondida que transforma review em auditoria perfeita. Oh-My-Pi é um harness muito bom. OpenCode também. Claude Code também. Todos erram. Todos dependem do modelo, do contexto e do pedido. Por isso eu não sei se preferiria Oh-My-Pi a OpenCode ou Claude Code como ferramenta principal. Ele entra na mesma prateleira: excelente, útil, mas não milagroso.
Mais uma anedota, sem virar prova de nada. Enquanto eu editava este post no Oh-My-Pi, pedi uma mudança localizada. Com Claude Code e OpenCode, quando peço isso num post bilíngue, normalmente eles alteram o trecho em PT-BR e o trecho equivalente em EN, só naquele range. O Oh-My-Pi fez metade certo: editou o PT-BR no lugar certo. Mas no EN decidiu retraduzir o arquivo inteiro do zero. Não sei por quê.
É só um caso. Não prova incompetência. Mas é curioso porque justamente derruba a fantasia de que Pi sempre economiza token. Nessa rodada, ele gastou muito mais. Eu nunca vi Claude Code ou OpenCode retraduzirem o post inteiro quando eu pedi uma edição pequena; eles costumam ser bons em mexer só no pedaço pedido.
Minha primeira impressão é que o OMP realmente tem mais tools e se esforça pra usá-las. Talvez até demais. Às vezes eu fico com a sensação de que ele força tooling em tarefa onde OpenCode e Claude Code seriam mais diretos ao ponto, e isso quase começa a piorar a resposta em vez de ajudar. Pode ser só impressão inicial, mas a sensação até aqui é essa: o OMP às vezes tenta demais pro próprio bem.
Então qual eu usaria?
Se o assunto é programação normal, eu continuaria alternando entre Claude Code e OpenCode.
Claude Code quando quero usar Opus e o plano Anthropic. OpenCode quando quero usar GPT 5.5 e não sofrer com Codex. Simples.
Oh-My-Pi eu colocaria na caixa de ferramentas, não como substituto obrigatório. Eu escolheria Oh-My-Pi quando o projeto tivesse muita coisa fora de source code:
- PDFs que precisam ser lidos;
- planilhas;
- SQLite;
- notebooks Jupyter;
- ZIPs e tarballs;
- imagens;
- páginas web que precisam virar texto;
- artefatos internos de outras execuções;
- necessidade de AST codemod com mais frequência.
Talvez em projeto de data science ele brilhe mais. Talvez em investigação de dados. Talvez em auditoria, migração, pesquisa com documentos, ferramenta interna cheia de SQLite e CSV e XLSX. Nesses cenários, a tool read universal é muito conveniente.
Pra CRUD Rails, backend Go, frontend TypeScript, CLI Rust, blog Hugo? OpenCode é tão bom quanto e mais polido.
E Pi puro? Eu só usaria se minha diversão fosse montar o harness em si. Nada errado com isso. Só não vou fingir que é o caminho pra quem quer terminar trabalho hoje.
Minha recomendação atual
Se você quer uma resposta curta:
- Use Claude Code com Opus 4.7 se você quer o melhor harness proprietário e pode ficar dentro do ecossistema Anthropic.
- Use OpenCode com GPT 5.5 se você quer usar o plano da OpenAI sem se prender ao Codex.
- Use Oh-My-Pi se você quer um harness mais flexível, com mais tools, especialmente pra projetos com arquivos e artefatos variados.
- Evite Codex se você tem alternativa. O modelo é bom. O harness atrapalha.
- Use Pi puro se você gosta de montar sua própria distro. Como ferramenta de trabalho imediata, eu começaria pelo Oh-My-Pi.
A analogia com Linux ajuda. Eu não uso Linux porque é “grátis”. Uso porque, pra mim, é a melhor ferramenta pro trabalho. As alternativas não chegam perto no meu fluxo. Mas isso não quer dizer que todo iniciante deveria largar Windows ou macOS amanhã e montar Arch na unha.
Mesma coisa com editor. NeoVim é tecnicamente fantástico. Eu adoro. Mas existe um motivo pra ele não ser tão mainstream quanto VS Code: não é produtivo no primeiro dia, a não ser que você já tenha experiência e tenha aprendido aos poucos. Se você precisa de produtividade agora, usa a ferramenta mais fácil que funciona out of the box. VS Code, Cursor, Windsurf, JetBrains, o que for. Entrega primeiro. Tweaka depois.
E olha que eu nem sou o cara de ficar fazendo rice de NeoVim o dia inteiro. Eu prefiro NeoVim porque as capacidades de edição são superiores às do VS Code, e porque gosto de ficar 100% no terminal. Editor GUI como VS Code ou Zed não me dá esse fluxo. Uso o mesmo editor localmente ou via SSH, combino com Tmux ou Zellij, rodo tudo em terminal moderno tipo Kitty, Ghostty ou Alacritty, e sou produtivo assim.
Nesse ponto, harness de LLM combina comigo. Oh-My-Pi, OpenCode e Claude Code já são terminal-based. Qualquer um deles encaixa bem no meu fluxo.
Pi cai nessa categoria. É NeoVim. Tecnicamente ótimo, elegante pra quem gosta de montar a própria oficina, mas não é a escolha certa pra todo mundo. É ferramenta pra quem gosta de tunar, entende o custo disso, e aceita passar tempo ajustando o harness como parte do hobby ou do trabalho. Pra maioria, comece pelo pacote que funciona.
Ou seja: Oh-My-Pi e OpenCode são bons. Escolha um e trabalhe. Não tem religião aqui.
O que me irrita é fanboy vendendo nome de ferramenta como se fosse argumento. “Usa Pi” não significa nada. Me diga o que ele resolve melhor. Me diga onde economiza tempo. Me diga que bug real ele evita. Me diga que fluxo fica impossível no Claude Code ou no OpenCode e trivial no Pi.
Aí sim temos conversa.
Até agora, minha leitura é chata: pra desenvolvimento de software normal, Oh-My-Pi e OpenCode performam parecido quando usam o mesmo modelo. Oh-My-Pi tem mais ferramentas e é mais flexível. OpenCode é mais coeso e polido. Claude Code continua sendo a régua quando o assunto é Opus. Codex continua sendo a opção que eu só usaria se não tivesse escolha.
Ferramenta ajuda. Harness importa. Mas quem ganha ainda é processo: prompt pequeno, escopo claro, teste rodando, revisão cuidadosa, commit frequente, engenharia de verdade.