A Controvérsia da LLM Rio 3.5. Plágio?

Essa semana apareceu uma controvérsia curiosa no mundinho de LLM de código aberto: a Rio 3.5 Open 397B, apresentada pela Prefeitura do Rio/IplanRIO no anúncio da plataforma Rio 3 Open como modelo aberto.
A acusação: na prática, o checkpoint publicado, ou seja, o arquivo de pesos do modelo, teria sido uma mistura direta do Nex-N2-Pro com o Qwen3.5-397B-A17B, sem crédito inicial à Nex.
O título do post tem interrogação de propósito. “Plágio” é uma palavra pesada, especialmente quando estamos falando de modelo sob licença permissiva. A pergunta correta não é só “pode usar?”. Em código aberto, quase sempre pode. A pergunta é: usou, modificou, redistribuiu e deu crédito corretamente? E, no caso de modelo de IA, tem outra pergunta tão importante quanto: foi transparente sobre o que de fato foi feito?
Minha conclusão curta, antes do textão: a evidência pública da Nex é forte. Forte o bastante pra dizer que o checkpoint inicialmente publicado da Rio 3.5 parece ter sido uma mescla quase linear de Nex-N2-Pro e Qwen3.5-397B-A17B.
A própria README da Rio foi alterada depois da issue da Nex para reconhecer Nex + Qwen e dizer que houve um “envio incorreto”.
Eu não reproduzi a análise tensor a tensor. Estou avaliando a evidência publicada pela Nex, o histórico público do Hugging Face e os testes que eu rodei separadamente no meu benchmark.
Isso não prova, juridicamente, “plágio” no sentido clássico. Mas mostra uma falha feia de atribuição e comunicação. E pra projeto público, com prefeitura, isso pesa mais.
O que a Prefeitura do Rio anunciou
Em abril, a Prefeitura publicou uma notícia dizendo que a IplanRio apresentou a plataforma Rio 3 Open, “uma família de seis modelos de inteligência artificial de ponta totalmente gratuita e aberta”.
O texto oficial dizia que a ideia era colocar o Rio como polo de inovação pública, capaz de desenvolver soluções próprias de IA “sem depender de plataformas estrangeiras”. Também destacava licença MIT, uso livre, modificação e até lucro sobre a tecnologia. Fonte: Prefeitura do Rio, 02/04/2026.
Uma reportagem do Mobile Time deu mais contexto: a família seria desenvolvida a partir do Qwen, modelo chinês da Alibaba.
O próprio João Cabaretta, presidente da IplanRio, teria dito: “O que fizemos foi pegar o modelo Qwen, já pronto, e a partir dele modificamos o modelo.” A reportagem também citava usos esperados na prefeitura: ler câmeras de segurança em busca de atividades suspeitas, analisar documentos de prestação de contas, gerar imagens e vídeos institucionais e atendimento ao cidadão.
Até aqui, nada absurdo. Pegar um modelo aberto e adaptar pra uso local é exatamente o que muita gente faz. Se a prefeitura conseguiu montar infraestrutura, adaptar modelo, documentar, publicar pesos, isso é bom. Eu sou a favor. Prefiro isso a mais um contrato fechado com SaaS estrangeiro que ninguém audita.
O problema começa na forma como a Rio 3.5 foi apresentada.
No Hugging Face, o repositório prefeitura-rio/Rio-3.5-Open-397B inicialmente dizia que o modelo era “developed by IplanRIO”, “Post-trained from Qwen 3.5 397B”, com MIT License e agradecimentos ao Qwen Team e ao SwiReasoning. Essa versão antiga ainda está acessível no histórico do Hugging Face: README antes da correção.
O card também prometia um modelo generalista de fronteira, com 397B parâmetros totais / 17B ativos, janela de contexto de 1.010.000 tokens e uso comercial/pesquisa liberado sob MIT. Ou seja: não era uma nota lateral. Era um lançamento com ambição alta.
Repara no detalhe: Qwen aparecia como base. A Nex, não.
E isso importa porque, na própria discussão da Nex, alguém corrigiu a narrativa dizendo que a Rio já creditava Qwen desde cedo. Está certo: o segundo commit do card do modelo já colocava base_model: Qwen/Qwen3.5-397B-A17B. Um comentário na issue também aponta isso: “They did say Qwen 3.5 397B was the base model from the beginning…”.
Então a acusação mais forte não é “omitiram Qwen”. É: creditaram Qwen, mas omitiram Nex-N2-Pro, justamente o componente que a análise de pesos da Nex diz ser majoritário na receita publicada.
Depois da issue aberta pela Nex, a README atual passou a dizer outra coisa:
“O modelo foi construído por meio de uma mescla de https://huggingface.co/nex-agi/Nex-N2-Pro e https://huggingface.co/Qwen/Qwen3.5-397B-A17B, seguida por On-Policy Distillation a partir de um modelo mais forte. Detectamos um envio incorreto na versão anterior, em que a versão base mesclada foi enviada em vez do modelo final destilado. Pedimos desculpas pela confusão.”
Fonte: README atual da Rio 3.5, alterada no commit a778c1e.
Essa frase muda bastante a história. Antes: “pós-treinado a partir do Qwen”. Depois: “mescla de Nex-N2-Pro e Qwen, seguida por destilação, mas subimos o arquivo errado”.
Pode ser verdade. Pode ter havido mesmo um envio errado. Mas, como observador externo, eu só consigo analisar o que foi publicado.
A acusação da Nex
A Nex abriu a issue nex-agi/Nex-N2#4 em 14 de junho. Em tradução/resumo meu, a acusação principal é direta:
prefeitura-rio/Rio-3.5-Open-397Bé apresentado como um modelo original de 397B treinado pela IplanRIO. Não é. Seus pesos são uma mescla direta, elemento a elemento, do nosso modelo, Nex, com a base oficialQwen3.5-397B-A17B— cerca de 0,6 Nex / 0,4 Qwen — e não encontramos evidência de treino próprio deles.
A Nex aponta duas evidências.
Primeira: comportamento de identidade. Segundo eles, o serviço da Rio usava um prompt de sistema embutido dizendo “You are Rio”. Removido esse prompt, eles fizeram 120 perguntas de identidade. O resultado reportado foi:
- “Nex”: 95/120, ou 79,2%.
- “Nex-AGI”: 88/120, ou 73,3%.
- “Rio”: 0/120.
Exemplo de resposta citado pela Nex:
“Eu sou Nex, da Nex-AGI. A Nex-AGI é uma aliança de ecossistema de modelos grandes, construída em conjunto pelo Shanghai Innovation Institute…”
Fonte: comentário da Nex sobre identidade.
Isso sozinho não prova tudo. Modelo se identificar como outro pode acontecer por contaminação de conjunto de dados, prompt de sistema, prompt de teste malfeito, ajuste fino reaproveitado. Mas é um sinal ruim quando o modelo supostamente “Rio” nunca diz “Rio” sem máscara e diz “Nex” com frequência alta.
A segunda evidência é mais séria: análise de pesos.
A hipótese da Nex é simples. Se Rio = α·Nex + (1−α)·Qwen, então, para cada tensor:
(Rio − Qwen) ≈ α · (Nex − Qwen)Eles reportam valores muito consistentes: experts roteados com α ≈ 0,571 ± 0,0016 e cos_fit 0,993; lm_head com 0,574 e 0,991; atenção por volta de 0,585 e 0,986; projeções de atenção linear por volta de 0,586 e 0,984. Fonte: comentário da Nex sobre análise de pesos.
Essa é a parte que mais pesa. Similaridade alta entre modelos da mesma família não seria surpresa. Mas colinearidade tensor a tensor nesse nível é outra coisa. Se a conta reproduz em todos os tensores, não parece “treinamos algo parecido”. Parece mescla.
O ponto fraco: até alguém reproduzir independentemente, isso continua sendo uma análise apresentada pela parte interessada. O ponto forte: é uma análise técnica falsificável, não só print de chat.
O tweet da Nex
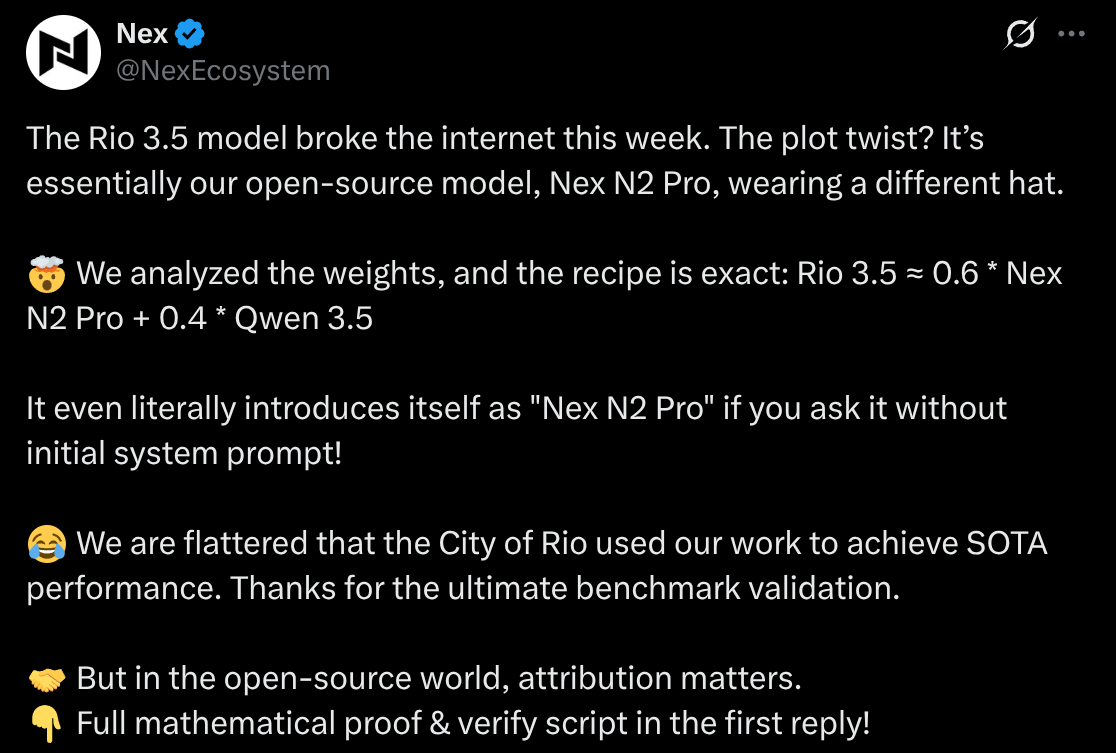
O tweet da Nex resume a acusação em tom de meme:
“O modelo Rio 3.5 quebrou a internet esta semana. A reviravolta? Ele é essencialmente nosso modelo de código aberto, Nex N2 Pro, usando outro chapéu.”
E continua:
“Analisamos os pesos, e a receita é exata: Rio 3.5 ≈ 0,6 * Nex N2 Pro + 0,4 * Qwen 3.5”
Também repete a parte de identidade:
“Ele literalmente se apresenta como ‘Nex N2 Pro’ se você perguntar sem prompt de sistema inicial!”
E fecha com a frase mais importante:
“Mas, no mundo do código aberto, atribuição importa.”
É isso. A parte mais importante não é “usaram nosso modelo”. Modelo de código aberto existe pra ser usado. Se a análise estiver correta, a reclamação é: teriam usado, se beneficiado da performance herdada, anunciado resultados, mas só dado o crédito depois que a Nex expôs a mistura.
Mas o que é Nex-N2-Pro?
Antes de continuar, vale explicar quem é a Nex nessa história, porque ela também não surgiu do vácuo.
No model card oficial, a Nex descreve o Nex-N2 como “an agentic model with Agentic Thinking”.
Marketing à parte, a promessa é clara: não ser só um modelo bom de chat, mas um modelo ajustado pra tarefas longas de agente. Programação, chamada de ferramentas, execução no terminal. Esse tipo de fluxo chato em que o modelo precisa planejar, executar, ver feedback do ambiente, corrigir e iterar.
E sim: ele também é baseado em Qwen. O próprio card diz que os dois modelos da família foram pós-treinados em cima da série Qwen3.5:
- Nex-N2-Pro: construído sobre
Qwen3.5-397B-A17B. - Nex-N2-mini: construído sobre
Qwen3.5-35B-A3B-Base.
Então a Nex não está dizendo “criamos uma arquitetura base do zero”. Ela está dizendo: pegamos Qwen como base e fizemos um pós-treino voltado a agentes em cima. A diferença prometida está nesse pós-treino.
Eles chamam o framework de Agentic Thinking, dividido em duas ideias:
- Adaptive Thinking: o modelo decide quando pensar pouco e agir rápido, ou quando gastar mais raciocínio em decisões críticas.
- Coherent Thinking: manter um paradigma de raciocínio consistente entre tarefas gerais, programação e tarefas de agente, em vez de tratar raciocínio, uso de ferramentas e execução como ilhas separadas.
Também há detalhes práticos: recomendam um fork customizado do sglang, usam reasoning-parser qwen3, tool-call-parser qwen3_coder, falam em suporte robusto a chamada de funções e listam testes de agente/programação onde o Nex-N2-Pro ficaria perto de modelos proprietários como GPT-5.5 e Opus 4.7.
Claro, teste de fornecedor sempre precisa de sal. Mas a tese é essa: Qwen cru é a base; Nex é o pós-treino e empacotamento de agente que deveria transformar essa base num modelo melhor pra trabalho real de agente.
Isso bate com meu benchmark independente. O Qwen3.5-397B-A17B base foi mal, 42/C. O Nex-N2-Pro foi bem, 83/A. Mesma base, diferença brutal. Pelo menos no meu teste de Rails/RubyLLM, o valor da Nex não parece ser “tem 397B parâmetros”. Qwen já tinha isso. O valor está em ter corrigido comportamento de agente que o Qwen base não tinha: usar API real, terminar a tarefa, validar ambiente, lidar com erro.
Essa distinção importa pra controvérsia da Rio. Se a Rio 3.5 usou Nex como ingrediente principal, não é só “usou Qwen com outro nome”. Ela teria usado justamente a parte que tornava o Qwen útil em tarefas de agente. E essa parte era trabalho da Nex.
O que a Rio respondeu, na prática
A resposta pública mais concreta, até onde consegui verificar, foi a alteração da README no Hugging Face. A Rio passou a dizer que:
- O modelo é construído via mescla de Nex-N2-Pro e Qwen3.5-397B-A17B.
- Depois disso haveria uma etapa de On-Policy Distillation, ou destilação on-policy, a partir de um modelo mais forte.
- O checkpoint inicialmente enviado seria a “versão base mesclada”, não o modelo final destilado.
- Eles estariam trabalhando pra reenviar o modelo correto.
Também há o histórico de commits do Hugging Face mostrando que, depois da issue, vários arquivos model-00001.safetensors até model-00097.safetensors e uma imagem de benchmarks foram removidos. Dá pra ver isso pela API de commits do Hugging Face.
Aqui entra meu ceticismo normal de engenheiro. “Subimos o arquivo errado” é uma explicação possível. Acontece. Mas quando o arquivo errado, segundo a análise da Nex, é exatamente uma combinação matemática de modelos de origem sem crédito inicial, e a correção vem uma hora depois da denúncia, fica difícil chamar de mero detalhe operacional.
Não impossível. Difícil.
O que é mescla de modelos
Pra quem não acompanha esse nicho, mescla de modelos, ou “model merge”, não é mágica. É uma técnica relativamente comum: você pega dois checkpoints compatíveis, normalmente da mesma arquitetura, e combina os pesos. A versão mais simples é literalmente uma interpolação linear:
modelo_final = 0.6 * modelo_A + 0.4 * modelo_BExistem variações mais sofisticadas, com mescla por camada, task vector, TIES, DARE, SLERP, pesos diferentes por módulo. Mas o conceito é esse: você não está treinando do zero. Você está combinando parâmetros já treinados.
Isso pode funcionar? Às vezes. Especialmente quando os modelos têm a mesma base e foram ajustados em direções complementares. Pode preservar capacidades de um e recuperar comportamento base de outro. Também pode piorar. Mescla é alquimia estatística: tem técnica, mas também tem muito teste empírico.
E, principalmente: mescla não custa nem remotamente o que custa treinar um modelo 397B. Você precisa baixar checkpoints enormes, rodar scripts, testar pesos, talvez fazer benchmark, talvez fazer ajustes. Não é zero trabalho. Mas não é “treinamos um modelo de fronteira”.
Se a evidência da Nex está correta, o checkpoint publicado era algo na linha:
Rio 3.5 ≈ 0.57 a 0.60 * Nex-N2-Pro + 0.40 a 0.43 * Qwen3.5-397B-A17BIsso parece mais trabalho de engenharia de integração do que treino de modelo. Não é o mesmo tipo de mérito técnico que pós-treinar ou destilar um 397B e apresentar isso como avanço próprio.
O que é destilação aqui
Destilação, ou distillation, é outra coisa. Em LLM, normalmente significa usar um modelo professor mais forte para gerar respostas, raciocínios ou preferências, e treinar um modelo aluno para imitar esse comportamento. Você pode destilar estilo, capacidade de raciocínio, formato de resposta, domínio específico, uso de ferramenta. O aluno pode ser menor, mais barato, mais rápido, ou simplesmente adaptado a um objetivo.
A README corrigida da Rio fala em On-Policy Distillation from a stronger model. Traduzindo livremente: eles teriam usado um modelo mais forte para gerar dados ou sinais de treino durante uma política de geração mais próxima do próprio aluno, e então treinado a Rio 3.5 final.
Isso, se existir, é trabalho real. Exige pipeline, dados, computação, avaliação. A questão é que a Nex não analisou esse suposto modelo final destilado. Ela analisou o checkpoint que estava publicado. E a própria Rio agora diz que aquele checkpoint era a “versão base mesclada” enviada por engano.
Então o estado factual é:
- checkpoint publicado inicialmente: acusado de ser uma mescla Nex + Qwen;
- README inicial: creditava Qwen, não Nex;
- README corrigida: reconhece mescla Nex + Qwen e diz que o final destilado não era aquele;
- modelo final correto: em aberto, até ser reupado e analisado.
Sem o checkpoint final, não dá pra avaliar a destilação. Dá pra avaliar a comunicação.
A licença: Apache permite, mas normalmente exige preservar avisos
Aqui é onde muita discussão online fica burra.
Não sou advogado e isso não é parecer jurídico. Além disso, a aplicação exata de licenças de código aberto a pesos de modelo ainda tem zonas cinzentas. Mas, pela leitura prática da Apache-2.0, a regra operacional não é “use e apague os rastros”.
Nex-N2-Pro declara licença Apache-2.0 no Hugging Face: README do Nex-N2-Pro. Qwen3.5-397B-A17B também declara Apache-2.0: README do Qwen3.5-397B-A17B.
Apache-2.0 é permissiva. Ela permite reproduzir, modificar, criar derivados, sublicenciar e distribuir. Inclusive comercialmente. Então não é “roubo” simplesmente porque usaram Nex e Qwen. Se a licença permite, usar faz parte do jogo.
Mas permissiva não significa “sem obrigação nenhuma”. A licença Apache-2.0 exige, entre outras coisas:
- dar aos recipientes uma cópia da licença;
- marcar arquivos modificados com avisos proeminentes de mudança;
- preservar avisos de copyright, patente, marca e atribuição da forma fonte;
- incluir NOTICE quando o trabalho original tiver NOTICE aplicável.
A Rio 3.5 inicialmente declarou MIT License e creditou Qwen/SwiReasoning, mas não Nex. Se o checkpoint distribuído era de fato derivado de Nex-N2-Pro, isso é no mínimo uma falha de atribuição. Pode ser corrigível. Parece ter sido corrigido parcialmente na README. Mas o erro aconteceu no lançamento, justo no momento de maior visibilidade.
E tem mais uma nuance: não dá pra simplesmente pegar dois componentes Apache-2.0, gerar um derivado e anunciar o pacote resultante como se fosse apenas MIT, sem preservar as obrigações Apache dos upstreams.
Apache-2.0 é permissiva e permite distribuir derivados sob termos diferentes para as suas modificações, mas com condição: você ainda precisa entregar a licença Apache, preservar avisos de copyright/atribuição e carregar NOTICE quando existir.
Então “MIT” pode até aparecer como licença da camada adicionada pela Rio, mas não pode apagar a Apache-2.0 de Nex e Qwen nem dar a entender que o derivado inteiro ficou livre dessas obrigações. Se o card original dizia só MIT e não trazia os créditos/avisos Apache aplicáveis, isso pode deixar de ser só gafe de etiqueta e virar possível problema de conformidade de licença.
E aqui tem uma ironia: eles poderiam ter evitado 90% da controvérsia com uma frase honesta desde o começo:
“Rio 3.5 é uma mescla/ajuste fino construído sobre Nex-N2-Pro e Qwen3.5-397B-A17B, com adaptações da IplanRIO para português e uso público.”
Pronto. Talvez ainda reclamassem politicamente, mas a crítica técnica ficaria muito mais fraca. O problema é parecer que você fez sozinho.
Quanto trabalho parece ter tido?
Essa é a parte especulativa, então vou marcar como especulação.
Se o que foi publicado era só a mescla base, o trabalho técnico pode ter sido bem menor do que a narrativa pública sugere. Fazer mescla de dois modelos gigantes não é apertar um botão no navegador, claro. Você precisa de armazenamento, scripts, máquina, validação, lidar com shards, enviar quase uma centena de safetensors, rodar testes, escrever documentação. Dá trabalho operacional.
Mas não é o mesmo tipo de trabalho que treinar, pós-treinar ou destilar um 397B de verdade.
E a frase “modelo de IA aberta treinada no Rio com financiamento público ao longo do último ano”, como disse Eduardo Cavaliere no tweet, cria uma expectativa bem diferente de “fizemos uma mescla de dois modelos Apache e talvez uma destilação depois”.
Rafael Coelho respondeu em outro tweet que não teriam gasto dinheiro público e que fizeram um swap de códigos de treino velhos por créditos de GPU. Pode haver uma explicação administrativa aí, mas pra quem está de fora a comunicação fica confusa.
Não estou afirmando irregularidade administrativa. Estou dizendo que a narrativa pública ficou inconsistente.
E mesmo a cifra de R$ 500 mil, citada na reportagem do Mobile Time sobre a geração anterior, precisa de escala. Em pesquisa séria de LLM, isso não é muito dinheiro. Some salário de alguns pesquisadores, infraestrutura, armazenamento, horas de GPU em nuvem, tentativas que falham, avaliação, engenharia de dados, e esse valor some rápido. É troco perto do custo de treinar ou pós-treinar modelo grande de verdade.
Então eu não usaria “R$ 500 mil” como prova automática de desperdício. Não é por aí. O ponto é outro: esse valor também não sustenta, sozinho, a narrativa de que foi feito um treinamento pesado e original de um modelo 397B. Pra esse tipo de escala, pesquisa séria gastaria muito, muito mais.
Foi financiado publicamente? Não foi? Custou R$ 500 mil na geração anterior? Foi crédito de GPU? Foi treino de um ano? Foi mescla? Foi destilação? Foi envio errado?
Talvez todas essas frases tenham contextos diferentes. Mas quando a comunicação técnica é ruim, o público junta tudo e vira bagunça.
O que meu benchmark diz sobre Nex e Qwen
Agora vem a parte em que eu consigo falar com dado próprio. No meu llm-coding-benchmark, eu testei tanto o Nex-N2-Pro quanto o Qwen 3.5 397B A17B base.
Meu benchmark mede uma tarefa específica de programação/Rails. Ele é útil como sinal, não como avaliação geral de capacidade.
Não testei a Rio 3.5 diretamente por um motivo simples: ela é grande demais pra minha máquina local. Meu Strix Halo tem 128 GB de RAM unificada, ótimo pra muita coisa, mas não pra rodar um 397B desse porte com folga. Pra testar direito eu teria que alugar máquina em nuvem, lidar com configuração, baixar centenas de gigabytes, organizar shards, subir servidor de inferência, pagar por hora, e ainda correr o risco de o checkpoint correto nem estar disponível no momento.
Não estava a fim desse trabalho todo pra um post de análise rápida. Então fiz a melhor aproximação disponível: testar os originais que a própria controvérsia coloca na receita, Nex-N2-Pro e Qwen3.5-397B-A17B. Se a Rio publicada era basicamente uma mescla desses dois, e se não há evidência pública de muito trabalho efetivo em cima daquele checkpoint, comparar os ingredientes já diz bastante. Não substitui teste direto da Rio, mas coloca a alegação de performance em perspectiva.
E tem outro detalhe: no model card antigo da própria Rio, a tabela dizia “Gains Over Base Model”, mas a Rio não ganhava do Qwen 3.5 base em tudo.
Ela perdia em MMLU-Redux (94,6 vs 94,9), MMMU-Pro (78,4 vs 79,0) e VideoMMMU (81,6 vs 84,7), empatava em MCP-Atlas (74,2 vs 74,2), e em alguns casos ganhava por margem pequena, como MMLU-Pro (88,0 vs 87,8) e MathVision (89,1 vs 88,6). Então mesmo pelos números auto-reportados, sem auditoria independente, a história era mais “melhora em vários benchmarks” do que “melhor que Qwen em tudo”.
E, sim, onde a Rio dizia ganhar do Qwen, isso também combina com a hipótese da Nex: o Nex-N2-Pro já era melhor que o Qwen base justamente por causa do trabalho da Nex. Eu vi isso no meu próprio benchmark: Qwen3.5-397B-A17B base fez 42/C, enquanto Nex-N2-Pro fez 83/A. Então uma Rio que mistura Nex com Qwen pode muito bem parecer melhor que Qwen. Para o checkpoint publicado, a explicação mais simples não é “a Rio inventou uma técnica milagrosa”; é “ela herdou boa parte do ganho que a Nex já tinha produzido em cima do Qwen”.
Commits relevantes:
11a9c68: adiciona Nex-N2-Pro, 83/100, Tier A.e2af88c: adiciona Qwen 3.5 397B A17B base, 42/100, Tier C.
Na tabela final do benchmark, o Nex ficou assim: rank #10, 83/100, Tier A.
Nex-N2-Pro | 83 | A | RubyLLM OK | OpenRouter | 25m | freeO Qwen base ficou assim: rank #28, 42/100, Tier C.
Qwen 3.5 397B A17B (base) | 42 | C | RubyLLM não OK | OpenRouter | 15m | ~$0.58Esse é um controle interessante. Mesmo backbone, resultado completamente diferente.
O Qwen base alucinou a API do RubyLLM (chat.system, chat.user, response.text) e ainda criou o app dentro de um diretório aninhado chat-app/, violando o formato esperado pelo benchmark.
O Nex, por outro lado, usou a API real: RubyLLM.chat, chat.ask, response.content, subiu localmente, passou Docker, compose e chat real via OpenRouter. O relatório compara isso diretamente: Qwen base 42/C vs Nex ajustado 83/A, salto de 41 pontos.
Isso coloca a Rio 3.5 em perspectiva. Se ela realmente era 60% Nex + 40% Qwen base, faz sentido ela herdar bastante da capacidade de agente do Nex. Mas também faz sentido suspeitar que misturar 40% de um modelo que, no meu teste, foi muito pior em programação, possa degradar o Nex puro em certos cenários.
Então não vou afirmar “Rio é pior” como medição minha. O que dá pra dizer é: o componente Nex é bom; o componente Qwen base foi ruim no meu teste; uma Rio que fosse só Nex diluído com Qwen base não deveria ser vendida como avanço óbvio sobre Nex puro sem benchmark reproduzível contra o próprio Nex. Pelo que foi publicado até agora, não parece que o trabalho adicional em cima da mescla tenha melhorado a posição de forma demonstrável. Se melhorou, publiquem o modelo correto e os testes reproduzíveis.
E mesmo o Nex, que foi muito bom, não ficou no topo do meu ranking de modelos abertos ou quase abertos. Ele marcou 83. Os melhores até aqui foram Kimi K2.6 e GLM 5.2 com 87, e Kimi K2.7 Code com 86. Nex é Tier A, gratuito, impressionante. Mas não é mágica. É um bom ajuste fino voltado a agentes em cima de uma família que, crua, tropeça feio em APIs de biblioteca.
Então, como usuário, minha conclusão prática é simples: se eu tivesse que escolher hoje, eu usaria Nex-N2-Pro direto. Não porque Rio seja automaticamente inútil para sempre, mas porque o checkpoint publicado não mostrou um ganho claro e auditável sobre o ingrediente mais valioso da receita. Se o ganho veio da Nex, por que não usar a Nex? A Rio só volta a ser interessante tecnicamente se aparecer o modelo final destilado correto, com avaliação reproduzível mostrando vantagem real sobre Nex-N2-Pro puro.
Então foi plágio?
Minha resposta honesta: eu não chamaria de plágio como conclusão jurídica. Eu chamaria de reapresentação mal atribuída do checkpoint inicialmente publicado, com forte evidência de mescla direta e uma correção posterior que só apareceu depois da exposição.
Código aberto não é “não pode usar”. Código aberto é “pode usar, mas respeite a licença e dê crédito”. Se Nex e Qwen estão em Apache-2.0, a prefeitura podia construir em cima. Podia fazer mescla. Podia fazer destilação. Podia publicar derivado. Podia até licenciar a parte dela sob MIT, desde que não apague obrigações dos componentes Apache e preserve os avisos exigidos.
O erro foi deixar a narrativa pública parecer criação própria, com crédito incompleto. E aí, quando a Nex apareceu com conta tensor a tensor, a README mudou.
Talvez exista um modelo final destilado de verdade. Se existir, publiquem. De preferência com:
- card claro dizendo base, mescla, destilação e dados de treino;
- licença compatível com Qwen e Nex;
- créditos explícitos;
- script de avaliação reproduzível;
- benchmark contra Nex-N2-Pro puro e Qwen base;
- explicação sobre o “envio incorreto”.
Isso encerraria boa parte da discussão técnica. Talvez não a política, mas a técnica sim.
O que dá pra aprender daqui
Essa história é um bom lembrete pra todo mundo que está surfando modelos abertos agora. A cadeia de derivação importa. Não por burocracia acadêmica, mas porque ela é parte da confiança.
Se você faz ajuste fino em cima de Qwen, diga Qwen. Se faz mescla com Nex, diga Nex. Se destila de um professor fechado, diga que destilou, mesmo que não possa nomear o professor. Se subiu o checkpoint errado, explique exatamente qual era o errado, qual é o certo, e como alguém pode verificar.
O pior caminho é tentar parecer maior do que é. Porque LLM de código aberto é um ambiente onde pesos são baixáveis, comparáveis e auditáveis. Você pode até esconder a narrativa por um tempo, mas não esconde álgebra linear.
No fim, a Nex talvez tenha feito a melhor validação involuntária do próprio modelo: se uma prefeitura usou Nex-N2-Pro como 60% da receita de um modelo anunciado como “estado da arte”, é porque o Nex é bom. Mas validação involuntária não paga a conta de crédito.
E crédito, no código aberto, não é frescura. É a moeda básica do jogo.