AI Agent Memory: Karpathy LLM Wiki and agentmemory in Practice
Update (May 23, 2026): after a week running agentmemory in personal production, I’m walking it back. The architecture it picked accumulates a class of bug that doesn’t close without rewriting half the system (BM25 reindex on every restart, 5-second data-loss window, wrong hook key on ~47% of Claude Code tool calls, etc). I started a Rust replacement called ai-memory that fixes those. See I Built a Memory System for Coding Agents: ai-memory for the full writeup, the alternatives ranking, and install instructions. The rest of this post still holds as background on how compaction works in the three agents, Karpathy’s LLM Wiki pattern, and why external memory matters.
Anyone running long sessions in Claude Code, Codex CLI or opencode has eventually seen the “context approaching limit” warning or watched the agent “forget” decisions made three hours ago. This post is a deep dive into how memory works in these agents today, where it breaks, and what you can do to get something closer to long-term memory. I read the source code directly: Codex (Rust), opencode (TypeScript) and Claude Code (TypeScript, via the leak that’s been circulating). Then I closed by testing agentmemory, an open source MCP server that tries to solve the problem systematically.
First things first: what is “context”
A language model (LLM) has no persistent memory. What it “remembers” during a conversation is just the set of tokens that fit inside its context window. Every message exchanged, every file read, every command output, every tool call — all of it goes into the window. When you use Claude Code, Codex or opencode, the agent is assembling a sequence of messages (system prompt + history + tools + tool output) and sending the whole thing to the API on every turn.
That has two direct effects. The first is behavioral: the agent performs best when the relevant part of the conversation is fresh in context, and degrades as important information gets buried under pages of ls and grep output. The second is financial: every token sent gets billed (or chipped off your quota), and large windows have higher latency. Opus 4.7 has a 1M context, GPT 5.5 too, but just because the window fits doesn’t mean it pays to fill it. The fuller it is, the slower inference gets and the pricier each request becomes.
That’s why every agent implements some form of compaction: when the context approaches the limit, the agent runs an extra LLM call that summarizes the conversation so far into something much shorter, dumps the raw history, and continues the session on top of the summary. The upside is obvious (more room to work) and so is the downside (the summarized part loses detail).
Let’s see how each of the big three pulls this off.
Codex CLI: per-model limit + explicit handoff
Codex CLI is open source (github.com/openai/codex), so we get to read it directly. The auto-compaction logic lives in codex-rs/core/src/session/turn.rs and fires like this:
let auto_compact_limit = model_info.auto_compact_token_limit().unwrap_or(i64::MAX);
// ... every turn ...
let total_usage_tokens = sess.get_total_token_usage().await;
let token_limit_reached = total_usage_tokens >= auto_compact_limit;
if token_limit_reached && needs_follow_up {
let reset_client_session = match run_auto_compact(
&sess, &turn_context, &mut client_session,
InitialContextInjection::BeforeLastUserMessage,
CompactionReason::ContextLimit,
CompactionPhase::MidTurn,
).await { /* ... */ }
}The limit is per model (auto_compact_token_limit comes from ModelProviderInfo). When it hits, Codex calls the LLM itself with a specific compaction prompt (in codex-rs/core/templates/compact/prompt.md):
You are performing a CONTEXT CHECKPOINT COMPACTION. Create a handoff summary for another LLM that will resume the task.
Include:
- Current progress and key decisions made
- Important context, constraints, or user preferences
- What remains to be done (clear next steps)
- Any critical data, examples, or references needed to continue
The response becomes the new context, prefixed with a preamble that literally says “another language model started to solve this problem and produced a summary of its thinking process.” Codex emits pre_compact and post_compact events that hooks can intercept (handled in codex-rs/core/src/hook_runtime.rs). Those hooks are the seam where external tools (like agentmemory) plug in to save state before compaction wipes the history.
opencode: 20K buffer + anchored summarization
opencode (github.com/sst/opencode) does the same thing with different math. In packages/opencode/src/session/overflow.ts:
const COMPACTION_BUFFER = 20_000
export function usable(input: { cfg, model, outputTokenMax? }) {
const context = input.model.limit.context
const reserved = input.cfg.compaction?.reserved
?? Math.min(COMPACTION_BUFFER, ProviderTransform.maxOutputTokens(input.model, input.outputTokenMax))
return input.model.limit.input
? Math.max(0, input.model.limit.input - reserved)
: Math.max(0, context - ProviderTransform.maxOutputTokens(input.model, input.outputTokenMax))
}
export function isOverflow(input) {
if (input.cfg.compaction?.auto === false) return false
const count = input.tokens.total
|| input.tokens.input + input.tokens.output + input.tokens.cache.read + input.tokens.cache.write
return count >= usable(input)
}By default, opencode reserves 20K tokens as a buffer between content and the window limit. When total tokens crosses usable(), it marks the session as needsCompaction = true and runs the compaction flow on the next turn. The summarization prompt (in packages/opencode/src/agent/prompt/compaction.txt) is more surgical than Codex’s:
You are an anchored context summarization assistant for coding sessions.
Summarize only the conversation history you are given. The newest turns may be kept verbatim outside your summary, so focus on the older context that still matters for continuing the work.
If the prompt includes a
<previous-summary>block, treat it as the current anchored summary. Update it with the new history by preserving still-true details, removing stale details, and merging in new facts.
Notice the difference: opencode keeps an “anchored summary” that gets updated on every compaction, instead of regenerated from scratch. The most recent turns stay verbatim, and only the older history gets collapsed. It’s a middle ground between Codex’s full handoff and keeping everything raw.
Claude Code: three levels of compaction + detailed summary
Claude Code is proprietary, but a recent leak exposed the source (TypeScript, same as opencode but with very different architecture). The code shows Anthropic went further than the competition: Claude Code has three levels of compaction running in parallel, not one.
The first is microcompact, time-based, in src/services/compact/microCompact.ts and timeBasedMCConfig.ts. When the gap since the last assistant message goes past 60 minutes, the server-side prompt cache (1h TTL) is guaranteed expired, so the whole prefix is going to be rewritten on the next request anyway. Before sending it, Claude Code clears the content of old tool results (Read, Grep, Glob, WebFetch, Bash, etc.) and replaces them with [Old tool result content cleared]. Shrinks the request size without entering the expensive summarization flow. Comment in the code:
/** Trigger when (now − last assistant timestamp) exceeds this many minutes.
* 60 is the safe choice: the server's 1h cache TTL is guaranteed expired
* for all users, so we never force a miss that wouldn't have happened. */
gapThresholdMinutes: numberThe second level is autoCompact, in src/services/compact/autoCompact.ts. Similar to opencode’s, but more carefully tuned:
const MAX_OUTPUT_TOKENS_FOR_SUMMARY = 20_000
export const AUTOCOMPACT_BUFFER_TOKENS = 13_000
export const WARNING_THRESHOLD_BUFFER_TOKENS = 20_000
export const ERROR_THRESHOLD_BUFFER_TOKENS = 20_000
export function getAutoCompactThreshold(model: string): number {
const effectiveContextWindow = getEffectiveContextWindowSize(model)
return effectiveContextWindow - AUTOCOMPACT_BUFFER_TOKENS
}Reserves 20K tokens for the summarization output, 13K of buffer for triggering the compaction, and has warning + error thresholds 20K below that limit (the TUI status bar turns yellow past the warning, red past the error). There’s also a circuit breaker: after 3 consecutive auto-compact failures, it stops trying — an internal comment reveals that without it “1,279 sessions had 50+ consecutive failures (up to 3,272), wasting ~250K API calls/day globally.”
The third level is sessionMemoryCompact in sessionMemoryCompact.ts, marked experimental, which ties into the persistent cross-session memory system.
The most visible difference vs Codex and opencode is in the summarization prompt. Where Codex asks for 4 short bullets and opencode asks for an update of the “anchored summary,” Claude Code asks for a 9-section explicit structure (src/services/compact/prompt.ts):
- Primary Request and Intent: Capture all of the user’s explicit requests and intents in detail
- Key Technical Concepts: List all important technical concepts, technologies, and frameworks discussed.
- Files and Code Sections: Enumerate specific files and code sections examined, modified, or created…
- Errors and fixes: List all errors that you ran into, and how you fixed them…
- Problem Solving: Document problems solved and any ongoing troubleshooting efforts.
- All user messages: List ALL user messages that are not tool results. These are critical…
- Pending Tasks: Outline any pending tasks that you have explicitly been asked to work on.
- Current Work: Describe in detail precisely what was being worked on immediately before this summary request…
- Optional Next Step: List the next step that you will take…
Section 6 (“All user messages”) is the unusual one: the summary has to contain a verbatim list of every user message that isn’t a tool result. Meaning even after compaction, Claude Code keeps your asks, literal. That’s why compacted sessions in Claude Code feel like they preserve the tone of the conversation better than Codex (where the handoff is more executive and less narrative).
There’s also a PARTIAL_COMPACT_PROMPT variant that summarizes only the recent stretch when a prior summary is preserved, and a PARTIAL_COMPACT_UP_TO_PROMPT to keep cache hits by placing the summary at the start. The /compact slash command is still around for manual force, and the PreCompact / PostCompact hooks run the same as the other agents.
Comparing the three side by side
| Claude Code | Codex | opencode | |
|---|---|---|---|
| Pre-compaction buffer | 13K (autocompact) + 20K (output) | per-model via auto_compact_token_limit | 20K (config compaction.reserved) |
| Compaction kinds | 3 (microcompact, autocompact, sessionMemoryCompact) | 1 (plus remote v1/v2 variants) | 1 (anchored, with updatable summary) |
| Summary structure | 9 fixed sections + <analysis> scratchpad block | 4 free-form bullets (progress, decisions, next, refs) | Update of the pre-existing “anchored summary” |
| Verbatim preservation | Lists every user message | No | Most recent turns kept intact outside the summary |
| Circuit breaker | Yes, 3 consecutive failures stop the cycle | Not documented | No |
| Hooks | PreCompact / PostCompact | pre_compact / post_compact (Rust) | no explicit compaction hooks |
| Time-gap microcompact | Yes (60min, synced with cache TTL) | No | No |
The design choices tell a story. Claude Code invests in preserving user narrative (the 9 sections, especially #6) and optimizing cache cost (gap-based microcompact, clean separation of 3 paths). Codex prioritizes handoff between models (the “summary produced by the other language model” preamble shows the expectation that the next turn might be executed by a different LLM). opencode picked incremental summarization: the anchored summary updates each cycle instead of being regenerated. Each strategy has trade-offs, but this is the first time you can look at all three side by side using real source.
“Vendor lock”? Doesn’t exist for this kind of memory
A worry that comes up a lot: by starting with Claude Code you get “locked in” and can’t migrate to opencode or Codex later. That’s a myth. Agent memory, as we saw, is just text. No proprietary binary format, no closed schema, no vendor-only state. Everything the agent carries is prompt + message history + context files.
In practice you can do a manual handoff between agents. Tell Claude Code: “write a markdown doc at ./HANDOFF.md with the current project state, decisions made, next steps, and any important context for a different agent to continue.” Out comes a well-written session, you close Claude Code, open opencode, say “read ./HANDOFF.md and pick up where it left off.” And opencode picks up from where Claude stopped, without meaningful loss (the loss is exactly the loss an internal compaction would have caused).
This pattern of explicitly exporting context is actually better than relying on automatic compaction. You decide when and what to preserve, instead of leaving it to the agent under token pressure.
The problem: long-term memory disappears alongside
Compaction solves the immediate problem (room in the context) but creates a subtler one: information from the start of the session is the first to go. If you spent 30 minutes on turn 5 exploring an architecture, decided three trade-offs and discarded two approaches, by turn 50 that whole exploration may have collapsed into a single bullet. If you need to revisit one of those discarded trade-offs (“why did we decide against Redis here?”), the agent doesn’t know anymore.
The workaround I’ve been using for months is to force the agent to write into files manually. On important projects I keep a ./.docs/ or ./docs/ directory with markdown files organized by topic: architecture, decisions, known gotchas, weird configurations, links to relevant issues. When something important happens in a session, I ask: “save this to ./.docs/<topic>.md”. Then on the next session, or after a compaction, the agent can re-read the file if it needs to.
The cost of this approach is discipline. I have to remember to ask. The agent won’t do it on its own. And I have to organize the files so it can find what it needs later (which usually means a MEMORY.md or CLAUDE.md at the root listing the topics).
There’s a more systematic way to do this. It’s called LLM Wiki, popularized by Andrej Karpathy in April 2026 in a GitHub gist.
Karpathy’s LLM Wiki pattern
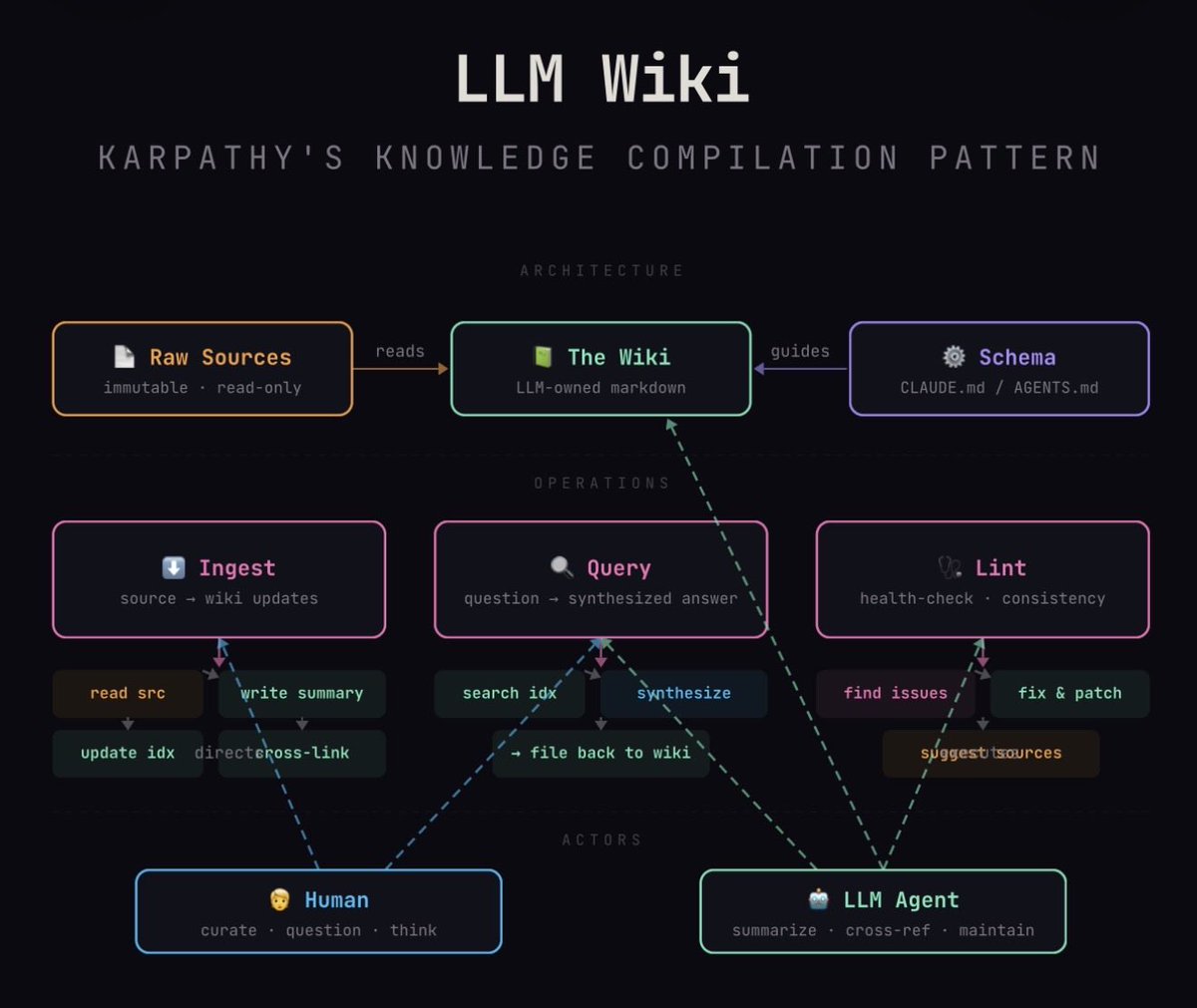
The idea is simple and powerful: instead of treating knowledge as something to retrieve on demand (RAG), treat it as something to compile over time, like code. The architecture has three layers:
- Raw Sources — immutable documents (papers, articles, transcripts, notes) that serve as source of truth.
- Wiki Layer — markdown files generated and maintained by the LLM. Each concept gets a page. Pages link to other pages. The LLM updates, cross-references, flags contradictions.
- Schema — a file (think
CLAUDE.mdorSCHEMA.md) that defines conventions: how to name pages, tag taxonomy, minimum structure per entry.
The workflow has three operations. Ingest: when a new source arrives, the LLM reads, extracts what matters, updates 10-15 existing pages, creates the missing ones, fixes cross-references. Query: questions get synthesized answers with citations; valuable insights become new pages. Lint: periodic passes detect contradictions, outdated claims, missing connections.
The core win over RAG is that knowledge compounds. RAG re-derives the answer on every query, starting from the same raw documents. The wiki synthesizes once, and the next query starts from the synthesis, not from raw material. For programming work this is gold: the first time you discover that a library has a weird timezone gotcha, it becomes a wiki page. The second time the topic comes up, the agent reads the page instead of re-discovering the problem.
The grunt work of maintaining a wiki always killed human wikis. That’s why they die. But LLMs are good at writing and repetitive maintenance. Karpathy’s bet is that we finally have a machine that does the boring work of keeping the wiki alive.
agentmemory: practical implementation of the pattern

I’d been doing this wiki by hand in ./.docs/ for months. This week I migrated to a tool that automates most of the process: agentmemory by Rohit Ghumare. It’s open source (Apache-2.0) and is literally an implementation of the LLM Wiki pattern with some extensions (confidence scoring, memory lifecycle, knowledge graph, hybrid search).
What it is, in practice:
- A Node daemon running locally on
127.0.0.1:3111(REST) and:3113(web viewer with timeline and session replay). Storage on SQLite + in-memory vector index, zero external dependencies. - An MCP server (
@agentmemory/mcp) that any MCP-compatible agent (Claude Code, Codex, opencode, Cursor, Gemini CLI, etc.) loads as a stdio server. Exposes 51 memory tools (memory_smart_search,memory_save,memory_sessions,memory_consolidate, etc.). - Hook plugins for Claude Code (12 hooks) and Codex (6 hooks) that capture observations automatically on every tool call, prompt and compaction event.
- Hybrid retrieval: BM25 + vector + knowledge graph, fused via Reciprocal Rank Fusion (RRF, k=60), with per-session diversification.
- 4-tier memory consolidation inspired by how the human brain processes memory during sleep: Working (raw observations) → Episodic (session summaries) → Semantic (extracted facts and patterns) → Procedural (workflows and decision patterns).
That last part is what makes it interesting. It’s not just a log of everything that happened. There’s decay (Ebbinghaus curve — memories that aren’t accessed decay), reinforcement (frequently accessed memories strengthen), stale eviction, contradiction detection and resolution. Exactly what’s missing from the “write to ./.docs/ by hand” pattern.
Quick install
Three options: npm global, npx, or (what I did) a dedicated prefix to dodge mise/Node version churn. The one-liner version from the project README:
npm install -g @agentmemory/agentmemory # once — `agentmemory` on PATH
agentmemory # spin up the daemon on :3111
agentmemory demo # seed sample sessions + validate recall
agentmemory connect claude-code # wire your agent (also: codex, cursor, gemini-cli, ...)For full details, the agentmemory README covers every variant (Docker, source build, Windows, embedding providers). For folks using mise to manage Node, it’s worth installing into a dedicated prefix (something like ~/.local/share/agentmemory-npm/) and starting the daemon via a systemd user unit, so global packages don’t vanish when mise swaps Node versions. But the README path works for most cases.
After the daemon is up, the main step is registering the MCP server in whichever agent you use.
For Claude Code, edit ~/.mcp.json:
{
"mcpServers": {
"agentmemory": {
"command": "/path/to/agentmemory-mcp",
"env": { "AGENTMEMORY_URL": "http://localhost:3111" }
}
}
}Verify with claude mcp list. You should see agentmemory: ✓ Connected.
For Codex CLI, edit ~/.codex/config.toml:
[mcp_servers.agentmemory]
command = "/path/to/agentmemory-mcp"
[mcp_servers.agentmemory.env]
AGENTMEMORY_URL = "http://localhost:3111"For opencode, edit ~/.config/opencode/opencode.json and add at the root of the object:
{
"mcp": {
"agentmemory": {
"type": "local",
"command": ["/path/to/agentmemory-mcp"],
"enabled": true,
"environment": { "AGENTMEMORY_URL": "http://localhost:3111" }
}
}
}After this, the three agents share the same memory server. Save a decision in Claude Code, run memory_smart_search in Codex and it shows up.
To push the agent toward consulting memory at the start of non-trivial tasks, it’s worth adding a line to CLAUDE.md (or equivalent):
At the start of non-trivial tasks, call `memory_smart_search` with the task
keywords. Use `memory_save` or `memory_lesson_save` when capturing decisions,
patterns, or preferences worth keeping.Otherwise the agent uses the tools when it judges it useful, but will skip them on purely exploratory sessions.
Practical upside: frictionless handoff
Here’s the thing that sold me. Remember the export-to-markdown pattern I described earlier, for migrating between agents? With agentmemory, it’s automatic. You save an architectural decision in a Claude Code session (memory_save type=architecture content="we use cookie store instead of session store because X"). Open opencode in the same project. Ask about session persistence. opencode calls memory_smart_search, retrieves the entry, and works from there.
Forget the “export to markdown, open the other agent, tell it to read”. Both agents read from the same place. Vendor lock stops making sense in this setup, because the memory source is external to both.
The trade-offs that stay
This isn’t magic. Some things to keep in mind:
The ideal embedding layer is a paid API (Voyage, OpenAI, Cohere). Without that, agentmemory uses local MiniLM via @xenova/transformers, which works but is slower on first ingest and less accurate on complex semantic queries. For anyone fine with a local model, it’s a real solution. If you want max recall quality, the API key is worth it.
The daemon runs as a permanent process. Needs a systemd unit (I run mine in user mode) or launchd on macOS. There’s no “start the server when you remember” — it has to stay up, or the plugin hooks miss events.
The 4-tier consolidation uses an LLM to process. Without a provider key configured, agentmemory runs in “no-op mode” — still indexes observations and searches, but doesn’t compress or consolidate. You still have the equivalent of the wiki, just without Karpathy’s “periodic lint.”
And like any new tool, the docs have holes. Some things to watch for that aren’t in the upstream README: the real state path depends on how the daemon is started (relative to its cwd), the iii engine’s port 49134 binds to 0.0.0.0 by default (passes through your firewall, worth checking), import-jsonl doesn’t honor the --dry-run flag despite the global help saying it does. Read the project README first, and be ready to debug when the docs fall short.
Memory is text. Text needs management.
The synthesis I take from all this is simple. Agent memory, at the root, is text. No proprietary schema, no binary format, no secret state. That’s liberating: you’re not locked to a vendor, you can move between Claude Code, Codex and opencode whenever you want, manually or via an external layer like agentmemory.
But loose text turns into garbage fast. Without compaction, the context window fills up and the agent gets slow and expensive. With compaction, you lose long-term memory. Without the discipline to save into files, important decisions evaporate on the next compaction. Without structure across files, they turn into a pile the agent can’t read efficiently.
The answer is a combination of four layers:
- Compaction solves the full-context-window problem. The big three (Claude Code, Codex, opencode) handle that by themselves.
- Manual markdown in
./.docs/or./docs/is the baseline fallback that always works, at the cost of demanding discipline from the programmer. - LLM Wiki pattern (Karpathy) lifts manual markdown into a structured workflow: source / wiki / schema, with ingest / query / lint.
- agentmemory (or similar MCP-based tools) automates the wiki, adds tiered consolidation, hybrid retrieval, memory lifecycle, and as a bonus serves the three agents off the same daemon.
The most underrated piece of all this is the compound effect. An architectural decision saved today is available for every future session, in any agent. A library gotcha discovered on Tuesday doesn’t need to be re-discovered on Sunday. It’s the kind of productivity that takes a few weeks to show up (you need critical mass of saved memories first) but that changes the game once it lands.
Worth testing. If you use Claude Code, Codex or opencode every day and never set up anything for long-term memory, start simple (a ./.docs/ in the current repo). When the frustration of the third “explanation I already gave” hits, install agentmemory.